How to ask cells what proteins they produce?
The Drop-Seq protocol, originally developed by Macosko et al. in 2015, is a high throughput method that enables the sequencing of the mRNA from a large number of cells. The power of this technology resides in the fact that during sequencing, one can distinguish where the original information came on a cell to cell basis. This allows one to make a gene expression map of the cell, or even to distinguish cell populations within a tissue. This method relies on droplet microfluidics and library preparation for Next Gen Sequencing (NGS): droplets allow for rapid and efficient compartmentalization using low reagent volumes and NGS allows for fast and high throughput analysis of single-cell gene expression.
Overview :
- General principle
- Why droplet microfluidics ?
- Process description
- Different genes, one cell ?
- Popularity
- The advantages of running pressure-controlled droplet production
- Conclusion
General principle

The DropSeq process relies on pairing one barcoded bead and one cell in a small droplet. after droplet formation, cell lysis occurs such that the polyadenylated RNA produced exclusively by this cell can specifically be captured on the bead. Capturing RNA with a single barcoded bead will allow the reconstitution of the information coming from that cell. Next, the mRNA is reverse transcribed along with the barcode into tagged cDNA, and PCR amplified. Finally, the resulting libraries are sequenced by NGS, and analyzed using various bioinformatics tools: cell barcode sequences are identified, transcript sequences linked to the barcodes mapped to a reference genome. All transcripts linked to one barcode form the gene-expression profile of a single cell.
Why droplet microfluidics?
The conventional way to isolate cells is by using Fluorescence Activation (FACS) to sort them into barcoded well plates (96 wells, 384 or 1536). This step is quite fast with the FACS currently available, but segregating thousands of cells into plates will result in a long process of pipetting for downstream steps like RT or PCRs, even on an automated platform. Droplet microfluidics allows for fast and low volume compartmentalization, usually up to a thousand drops produced per second with a volume of one nanoliter each. This consumes a thousand times less reagents and does not need high end FACS and liquid handlers, diminishing the costs per reaction. Think of a drop as a well from the plate, but smaller.

While all the compartmentalized steps will happen in a smaller volume, it is also make easier to pool afterwards thanks to initial cell barcoding: while combining the wells will be done by pipetting, droplets can be merged by chemical destabilization of their interface with the carrier fluid.
Process description
The encapsulation process is done using a microfluidic flow focusing junction chip, where all the reagents are brought to a nozzle where the carrier fluid (oil) will shear the water phase into small droplets at high speeds.
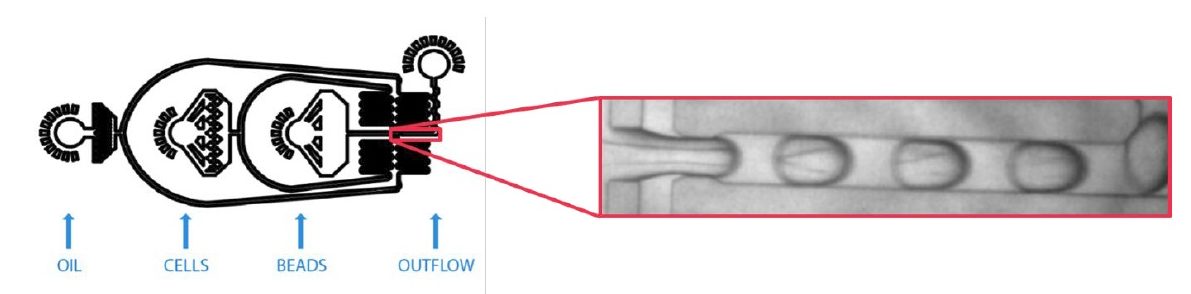
Once the encapsulation process is finished, the monodispersed emulsion obtained should look like this:
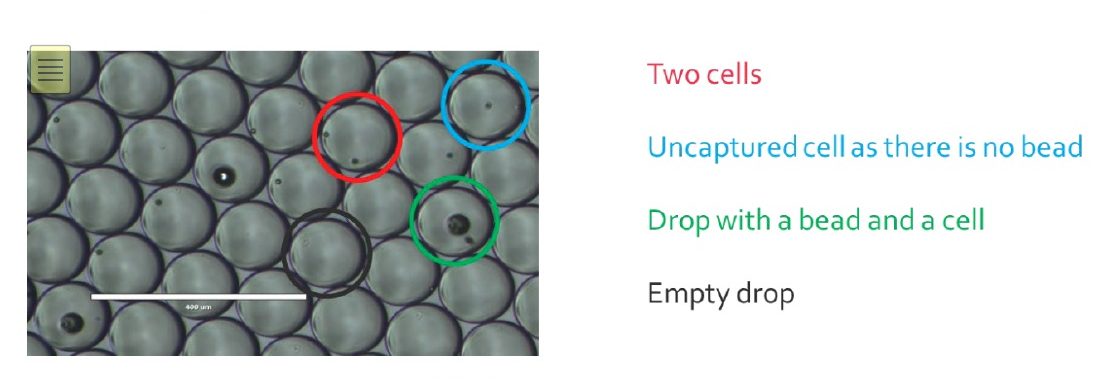
Empty drops will generate noise in the data, as they carry environmental RNA that can bind to beads once droplets get merged. For drops only containing a bead, most of the time it will not generate more noise as the unused barcodes will be destroyed later in the process. Cells that were not encapsulated will not be sequenced, as their RNA cannot be captured in drops, but will participate to the noise as the RNA released will bind to random beads. Usually, a Drop-Seq run allows one to capture around 5-10% of the input cells. This is due to the Poisson distribution, basically, this is a balance between having too many empty drops and having drops with 2 or more cells/beads, that will generate noise and unusable data during sequencing.
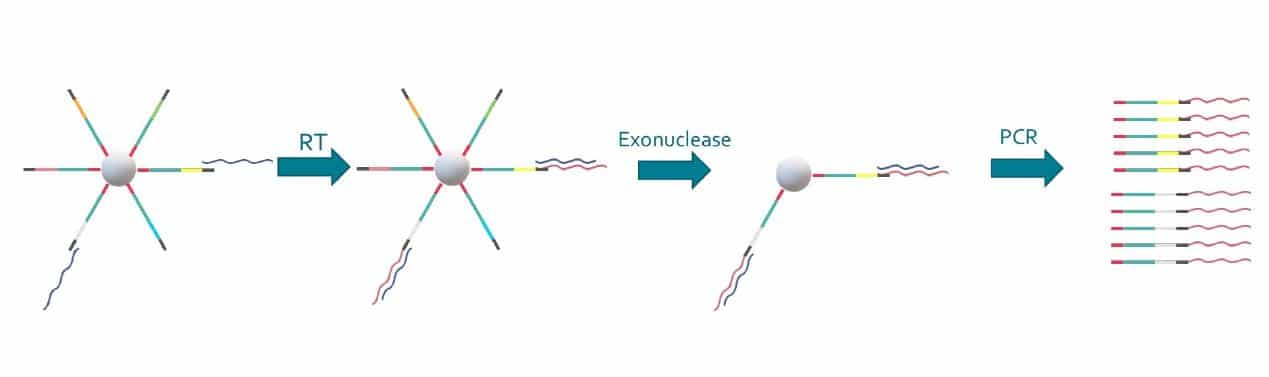
Special buffer components that are contained in the bead buffer will start cell lysis as soon as the drops are formed, and will carry on during droplet production. By the time the run is finished, all the cells will be lysed and RNA captured. This means the emulsion may be broken by merging all the drops and recovering the beads to start the molecular biology steps for sequencing the captured RNA. Reverse transcription (RT) will generate cDNA attached to the barcodes, and an exonuclease will be used to remove unused barcodes.
Different genes, one cell?
The power of the Drop-Seq method relies on how the microbeads are constructed: they are coated covalently with oligonucleotides that help capture RNA, barcode it in a way each bead contains unique barcode and diverse unique molecular identifiers to help quantifying captured RNA molecules.

First, there is the PCR handle, which will allow for the amplification of the generated cDNA molecules at the end of the process, mainly for amplifying the signal by generating more copies.
Second comes the barcoding sequence, which will be the same on each oligo from one bead, but different from one bead to another. All the sequences that contain a given barcode will then be associated to the same cell of origin.
Third comes the UMI, which stands for Unique Molecular Identifier. All the oligos on one bead have a different UMI sequence, so that different molecules of mRNA can be distinguished at the cell level. This allows for one to know how many mRNA of a given sequence have been produced by a cell.
Finally comes the capture sequence, which is usually a poly(T) tail to match the poly(A) tail of the 3’ end of mRNA. If you are only targeting a specific gene panel, you can also use complementary sequences to only capture those.
Popularity
The Drop-Seq protocol has been made open source by their original creator, and they even encouraged people to use it by fine tuning the process, publishing tutorials, tips and tricks, and finding suppliers for the specific reagents and consumables. Their protocol has been downloaded more than sixty thousand times in four years and there is an active community that is discussing and improving the protocols as we speak https://groups.google.com/forum/#!forum/dropseq
The literature around Drop-Seq represents more than a thousand papers around the world.
The advantage of running pressure-controlled droplet production
While the original protocol was developed using syringe pumps, pressure-controlled systems have a few advantages.
First, in terms of raw performance, pressure driven systems are faster to set up, easier to control and more stable over time, which allows for an emulsion of a better quality : the droplet size will be more homogeneous and start/stop populations will be smaller. This leads to better segregation of the cells, and less reagent use and less sample loss.
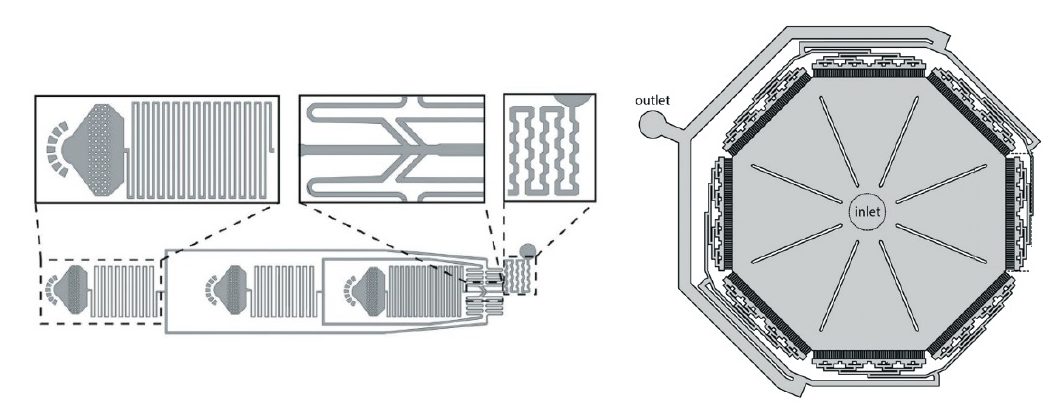
As the sample and beads need to be agitated throughout the experiment, it is usually done with a bulky stirring bar for syringe pumps. This leads to a dead volume that will not be injected in the chip. Pressure driven setups can be run using more conventional containers that make it possible to use an external agitation system, such asa standard lab vortexing system.
You can check out the work by M. Biocanin, et. al. from the technology development team of the LSBG lab at the Ecole Polytechnique Fédérale de Lausanne. They have adapted the chip to make it easily usable with both pressure systems and syringe pumps, re-engineered the nozzle to make it perform better, and refined the downstream process on a separate microfluidic chip that allows for robust and efficient bead processing while washing and post-processing of beads.
These optimizations lead to an increase in the number of beads recoved, diminished the contamination risks during washing steps, and allows for reliable processing of small volume samples.
Example of experimental set up
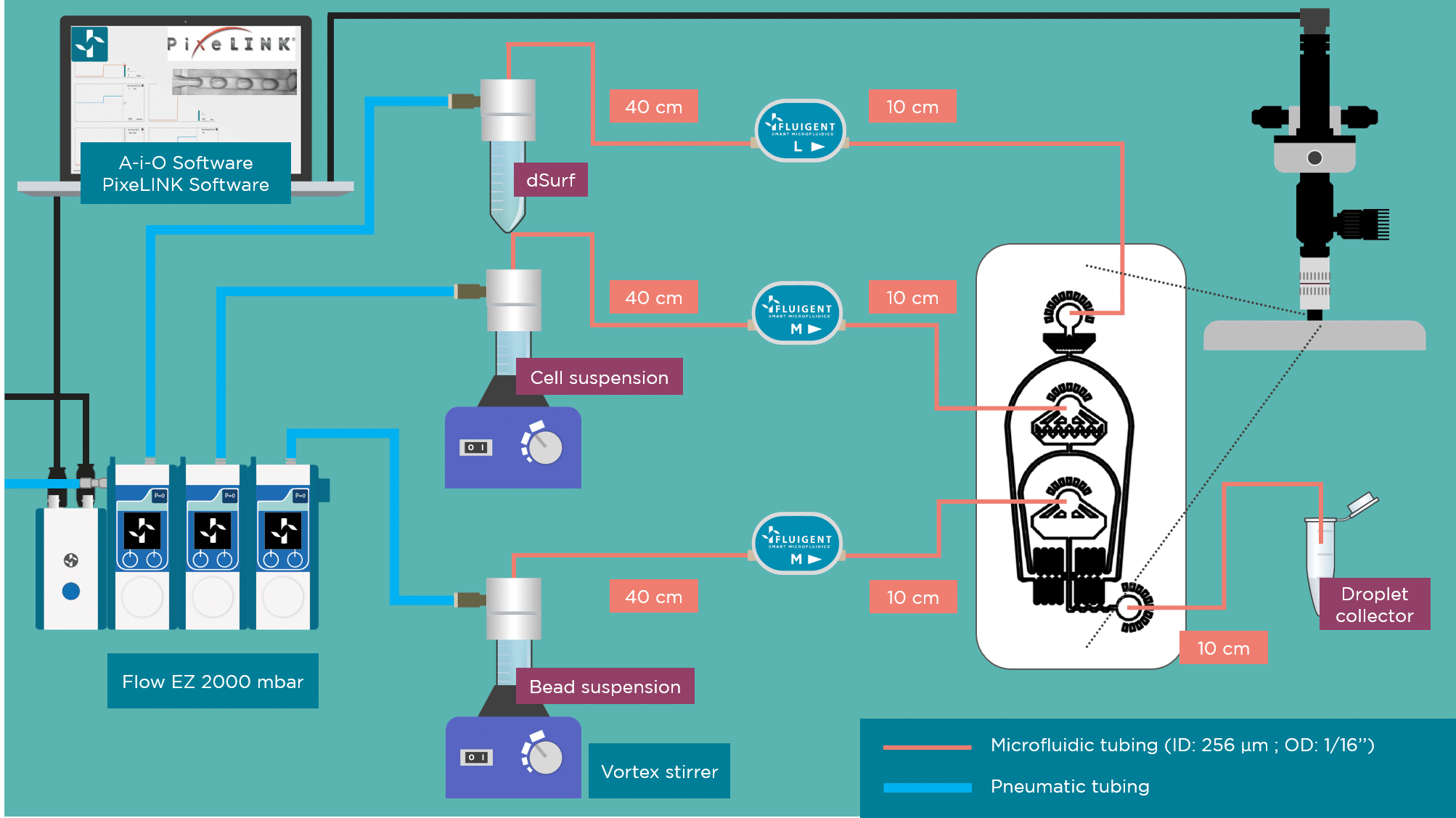
The experimental set up can be reproduced with Fluigent products, using 3 LineUp™ Flow-EZ™ or 1 MFCS-EZ™, 3 sensors for flow rate monitoring and a microscope. The chip is open source and is available from suppliers including: FlowJem, Nanoshift or uFluidix off the shelf. The beads are commercially available and can be purchased from ChemGenes.